做了与机器学习相关的项目好久了,但对机器学习一直没有一个系统的认识,导致在切入一些新的领域时力有不逮,总感觉理解有偏差或者理解困难,因此想系统地、详细地学习机器学习,就从周志华的西瓜书和Andrew Ng的机器学习视频开始吧。
众所周知, 机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新是研究计算机怎样模拟或实现人类的学习行为。
来自卡内基梅隆大学的Tom Mitchell提出的关于机器学习的定义较为人所接受,他定义的机器学习是,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升。
一般而言,我把机器学习分为监督学习、无监督学习和增强学习,而深度学习和大数据是拓展也是紧密的关联,如下图所示: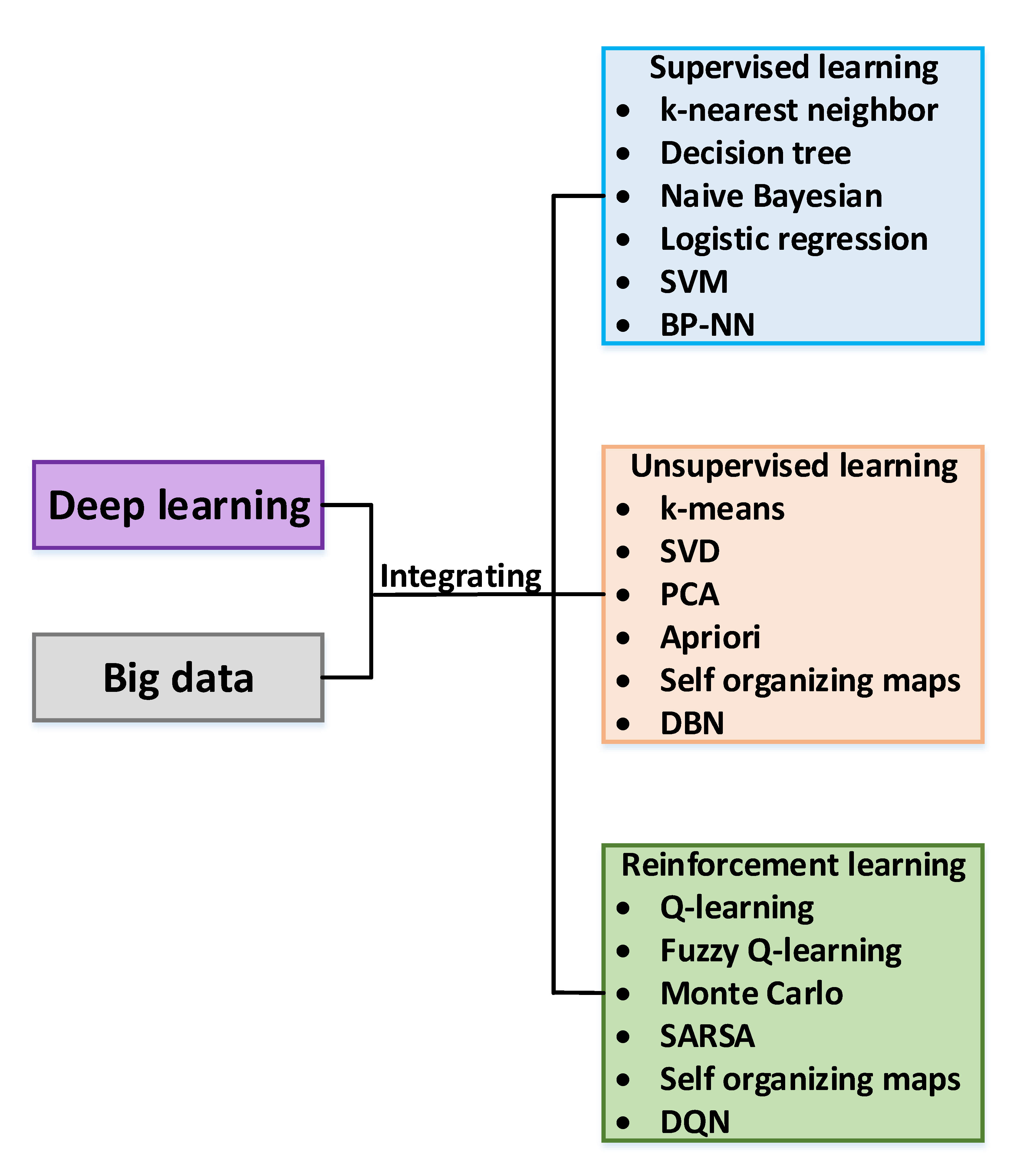
监督学习,顾名思义,就是有人指导你,告诉你这个学习正确与否。专业点来讲,就是数据集中每个样本都会带有一个正确答案,比如在西瓜分类里,“红瓤,有蒂”带有标签“甜”,“黄瓤,无蒂”带有标签“不甜”;在回归里,房价预测里每个样本都带有房价。分类和回归的区别在于预测的是一组离散的结果,而回归可以预测连续的输出。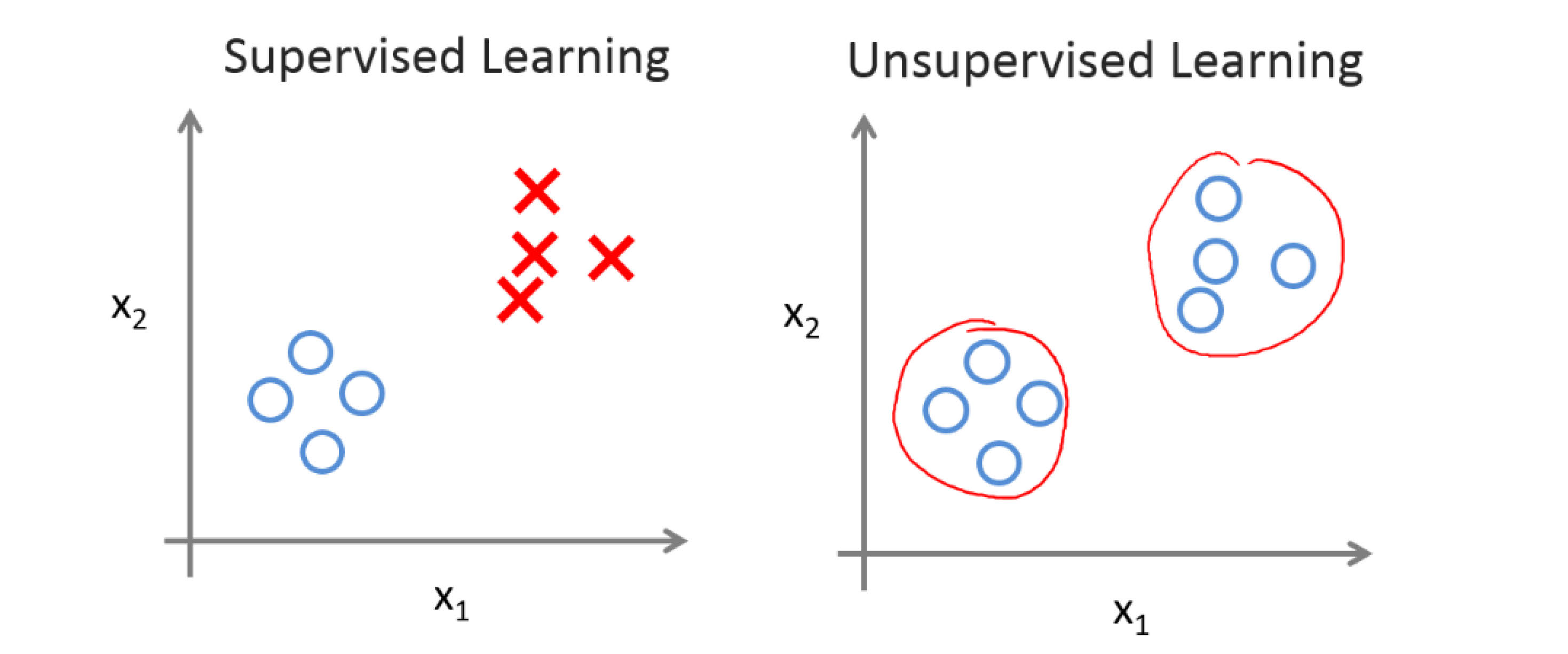
无监督学习,从上图可以看出,我们事先不知道样本是哪一类或者是哪一个值,也就是没有任何的标签或“答案”。一个比较著名的例子就是鸡尾酒宴问题:许多人坐在一起参加鸡尾酒会,大家都在同一时间说话,声音此起彼伏,重重叠叠,要想分离出不同人说话的声音,就是一个聚类问题,也是无监督学习问题。这个例子可能比较难懂,再说一个就是在无线通信中,有时会根据用户的行为特征对用户进行分类,便于进行一些资源的调度和统一管理,而如何判断一堆用户里哪些用户是类似的,比如上班族、学生党、旅客等,这就是一个典型的聚类问题。
增强学习则是要解决这样的问题,一个能感知环境的自治agent,怎样通过学习选择能达到其目标的最优动作。当agent(机器人,下棋,在无线领域则可以是用户、基站和operator)在环境中作出某个动作时,会产生不同的奖励值或者惩罚值,agent的任务就是从这个非直接的,有延迟的回报中学习,以便后续的动作产生最大的累积效应。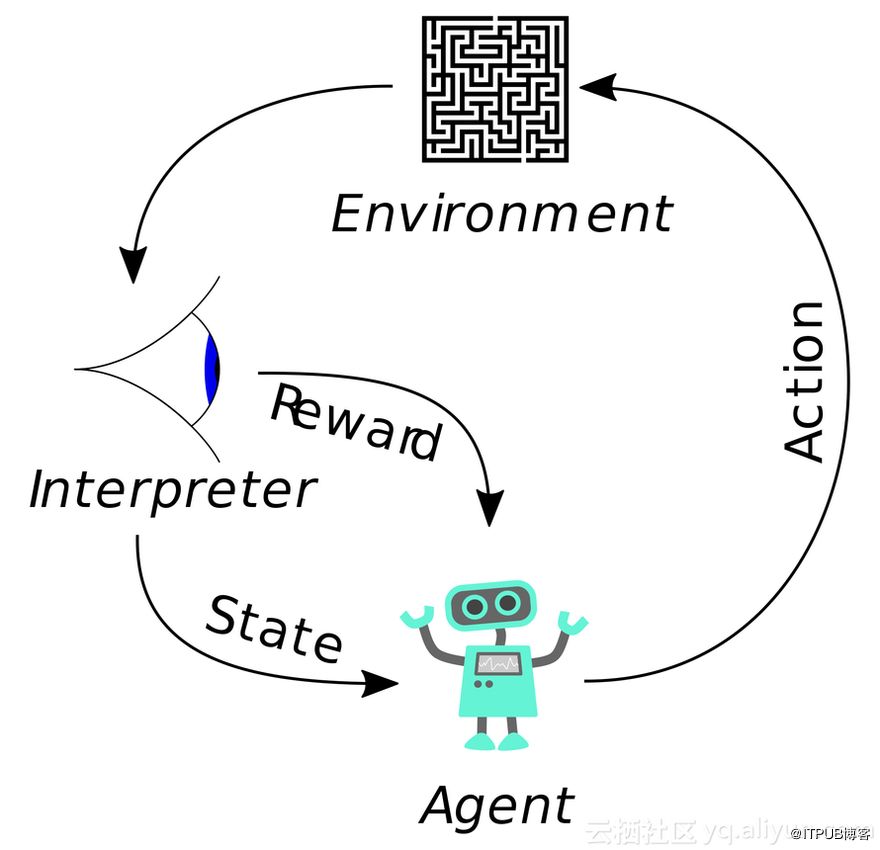
在后续的文章中,我们会对各个算法有比较详细的学习过程,敬请期待啦。