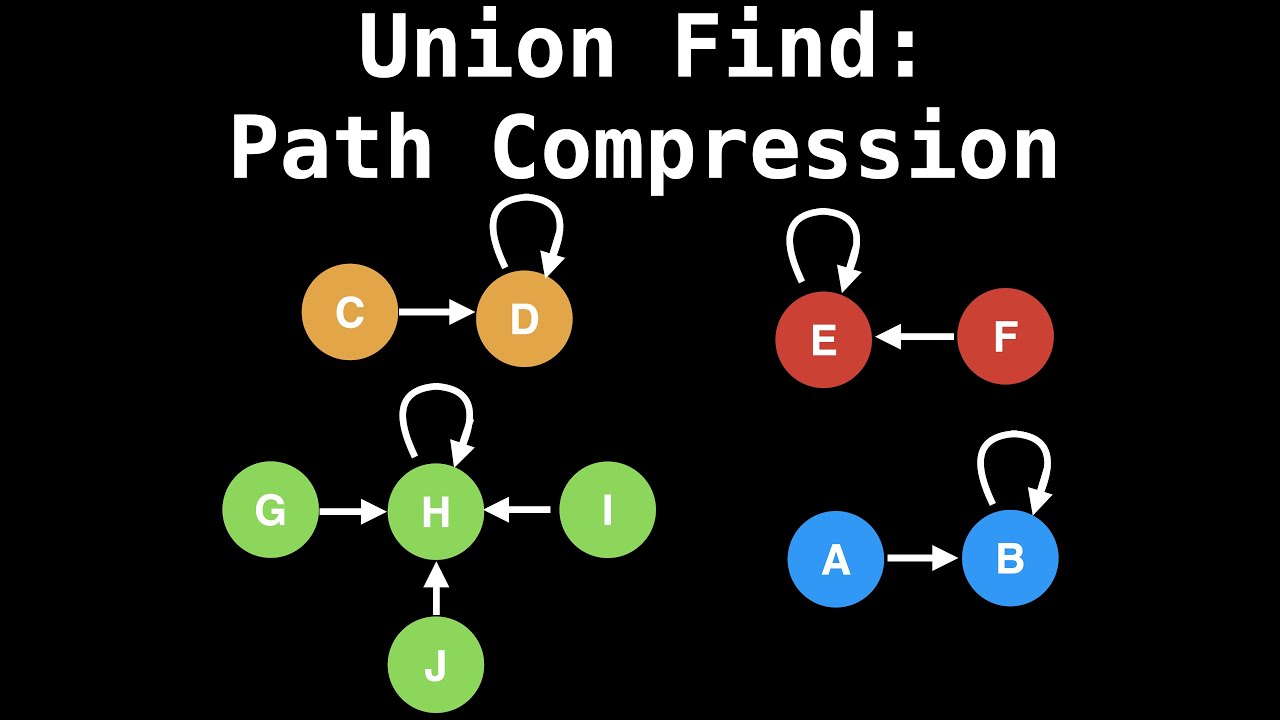

传统机器学习
Logistic Regression和percetron的异同
- 二者都是线性分类器
- 损失函数不同,LR是极大似然(交叉熵,对数似然函数,logistic损失(误差平方和损失)目标函数非凸),感知机使用的是均方损失函数(即最小化错误点到分离平面的距离)
- 逻辑斯蒂比感知机的优点在于对于激活函数的改进。LR为sigmoid函数,连续可导,概率解释能力,分类更好
感知机为阶跃函数,分段函数,分类粗糙,线性分类器参数学习,错误驱动的在线学习算法
损失函数L(w;x,y)=max(0, -ywx),如果训练集线性可分,算法必定收敛
不足:1.泛化能力不能保证;2.样本顺序敏感;3.不线性可分不收敛
改进:参数平均:投票感知机、平均感知机
拓展到多分类:构建输入输出联合空间特征函数,将样本(x,y)映射到特征向量空间
C分类问题,特征函数φ(x,y)=vec(yx),y为类别的one-hot向量表示 - LR的最大损失函数推导

最大似然概率
p(x|θ) 是条件概率的表示方法,θ 是前置条件,理解为在 θ 的前提下,事件 x 发生的概率,相对应的似然为L(θ|x)可以理解为已知结果为 x ,参数为 θ对应的概率,即:L(θ|x)=P(x|θ)
需要说明的是两者在数值上相等,但是意义并不相同,L 是关于 θ 的函数,而 P 则是关于 x 的函数
机器学习领域,我们更关注的是似然函数的最大值,我们需要根据已知事件来找出产生这种结果最有可能的条件,目的当然是根据这个最有可能的条件去推测未知事件的概率
对数函数不改变原函数的单调性和极值位置,而且根据对数函数的性质可以将乘积转换为加减式,这可以大大简化求导的过程:
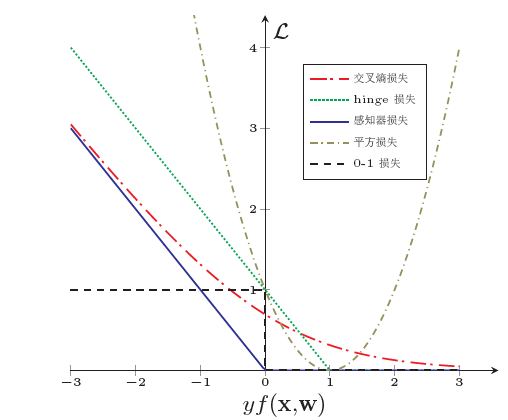
SVM
- 线性可分支持向量机(硬间隔)

- 线性支持向量机(软间隔)
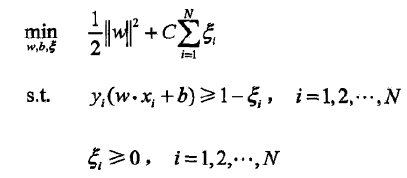
线性可分支持向量机的解W唯一但b不唯一
线性支持向量机学习等价于最小化二阶范数正则化的合页函数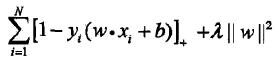
合页损失函数(正确分类且函数间隔大于1,损失为0,max(z,0))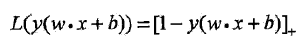
- 非线性支持向量机
通过非线性变换转化为高维特征空间中的线性分类问题,即核函数 - 序列最小化优化(SMO)算法
支持向量机的学习快速算法,固定αi之外的所有参数,然后求αi上的极值;不断重复直至收敛。 - 和LR的异同(https://www.cnblogs.com/zhizhan/p/5038747.html)
- 不考虑核函数,LR和SVM都是线性分类算法,分类决策面是线性的
- 本质是损失函数不同,LR是对数似然函数(基于概率),SVM是合页损失函数(基于几何间隔)
- SVM只考虑边界点,LR考虑全局,所以LR一般不用核函数
- SVM依赖数据距离测度,需要先做normalization,LR不受影响
- SVM损失函数自带正则(结构风险最小化),LR需要添加
One-Hot Encoding (dummy variables)
- 一组编码[0 0 1 0],一个为1其他为0,处理离散分类特征
- 许多算法基于向量空间计算,取值拓展到欧氏空间,扩充特征
- 特征空间大时,可结合PCA
- 树模型不太需要one-hot编码,对DT来说是增加树的深度
生成模型
- 监督生成模型
朴素贝叶斯、隐马尔科夫、条件随机场 - 非监督生成模型
受限玻尔兹曼机、GAN、自回归、变分自编码器、深度信念网络

模型融合:Stacking 和 Blending
- Stacking stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为特征加入训练集进行再训练,从而得到完整的stacking模型。
- 样例:假设我们有Training data(有label)和Testing data(无label),我们需要建立起模型对Testing data的label进行预测,我们利用两个基模型KNN和SVM进行stacking,首先我们需要训练好两个基模型
- 一、KNN(Base model 1) 5-fold Cross-Validation + Grid Search确定K的大小
- 二、SVM(Base model 2) 5-fold Cross-Validation + Grid Search确定参数 type 和 cost
- 三、Stacking(Meta Ensembling)
将training data划分成5个testing folds
为training data和testing中的每一个样本添加空属性M1、M2(model 1、2的输出),记为train_meta 和 test_meta
对于每一个test fold:
3.1)将其他4个folds作为一个traing fold,将此training fold作为model 1的输入,对test fold进行预测,将结果存放进train_meta的M1中,类似model 2 的结果存在M2中
3.2)将整个training data作为base model的输入,对testing data进行预测,model 1、2的结果分别存在test_meta的M1、M2中
将train_meta作为一个新模型S(也就是stacking model)的输入,对test_meta进行预测 - stacking方法从一开始就得确定一个Kfold,这个Kfold将伴随对基模型的调参、生成元特征以及对元模型的调参,贯穿整个stacking流程

- Blending Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
Adaboost,XGBoost,Bagging,LightBoost
- Boost算法 初始样本权重,每次训练得到模型赋予错分样本更大的权重,N次迭代后对N个模型进行加权叠加或投票,得到预测结果;串行过程,不好并行化,计算复杂度高,不适合高维稀疏特征
- XGBoost
- GBDT以CART作为基分类器,XGBoost支持线性分类器(L1,L2的逻辑回归或线性回归)
- GBDT优化使用一阶导数,XGBoost对代价函数进行二阶泰勒展开,支持自定义代价函数
- XGBoost加入正则项,包括树的叶子节点个数、叶子节点上score值(正则化是从bias-variance考虑,可以降低模型variance,降低模型复杂度,防止过拟合,传统GBDT没有?)
- 列采样(每个模型随机选取一些列),借鉴随机森林,目的是降低过拟合
- Shrinkage(缩减),相当于学习速率(xgboost中的eta)。xgboost在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间
- 并行化。不是像bagging,仍然是boost方式,并行是在特征排序上,
- xgboost在训练之前,预先对数据进行排序,然后保存成block结构,后面的迭代中重复的使用这个结构,大大的减少了计算量。在进行节点分裂时,计算每个特征的信息增益,各个特征的增益计算就可以开多线程计算。
- 分裂节点公式:

- lightGBM
- 训练速度更快,效率更高。
- 降低内存使用率。
- 更好的准确性。
- 支持并行和GPU学习。
- 能够处理大规模数据。
- 与XGBoost GBDT区别:
xgboost采用预排序算法进行特征分割,比较简单;LightGBM用的是histogram(直方图),将连续特征(属性)值存储到离散的bin中,加快训练速度和减少内存使用量
稀疏特征优化
xgboost是level-wise,多线程同时分类同一层叶子,但不加区分,开销大;lightGBM是leaf-wise的,每次找分类增益最大进行分裂,限制最大深度,防止过拟合
并行优化(feature parallel, data parallel, voting parallel)
- GBDT
- GBDT用的回归树
- GBDT 是以决策树为基学习器、采用 Boosting 策略的一种集成学习模型
- 与提升树的区别:残差的计算不同,提升树使用的是真正的残差,梯度提升树用当前模型的负梯度来拟合残差。
- 核心是每棵树学习的是之前所有树结论和的残差,所有树累加起来做最终结论
- 本质上,Shrinkage为每棵树设置了一个weight,累加时要乘以这个weight,但和Gradient并没有关系。

- 随机森林 Bagging的典型应用;随机采样(行、列),防止过拟合;剪枝、限制树深度
优点
- 在当前的很多数据集上,相对其他算法有着很大的优势,表现良好
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择 PS:特征子集是随机选择的
- 在训练完后,它能够给出哪些feature比较重要 PS:http://blog.csdn.net/keepreder/article/details/47277517
- 在创建随机森林的时候,对generlization error使用的是无偏估计,模型泛化能力强
- 训练速度快,容易做成并行化方法 PS:训练时树与树之间是相互独立的
- 在训练过程中,能够检测到feature间的互相影响
- 实现比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
缺点:
1、随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合
2、对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
决策树
- 决策树学习算法:特征选择、决策树的生成、剪枝(条件概率分布)
- ID3算法:信息增益;C4.5:信息增益比
- CART分类:基尼系数;CART回归:平方损失函数,用平方误差最小的准则(最小二乘法)求解每个单元上的最优输出值(每个叶子节点上的预测值为所有样本的平均值)。
- 决策树的生成通常使用 信息增益最大、信息增益比最大或基尼指数最小作为特征选择的准则。
过拟合和欠拟合
- 正则化 L1(L=∑|w|)和L2(L=||w||^2);L1的稀疏性,指的就是在加了L1正则项后,模型的解w,有很多分量都是0。引入L2正则时,代价函数在0处的导数仍是d0,无变化。而引入L1正则后,代价函数在0处的导数有一个突变。从d0+λ到d0−λ,若d0+λ和d0−λ异号,则在0处会是一个极小值点。代价函数求导。因此,优化时,很可能优化到该极小值点上,即w=0处。
- 提前停止 当测试集误差不再下降时停止可以避免过拟合
- dropout
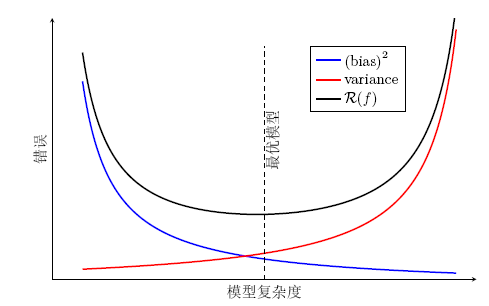
- 偏差-方差分解 在模型能力和复杂度之间取得一个较好的平衡

- 偏差高,模型拟合能力不够:增加数据特征、提高模型复杂度、减少正则化系数
- 方差高,模型过拟合(训练集错误低,验证集错误高):降低模型复杂度,加大正则化系数,引入先验、集成模型
参数估计
- 经验风险最小化 真实标签与预测标签的差异;最小二乘估计(最小均方误差);XX^T必须满秩,即rank(XX^T)=d+1,X中每行特征之间线性不相关;样本数小于特征数也不可逆,存在多组解;当XX^T不可逆时,可用PCA消除相关性
- 结构风险最小化 正则化;岭回归(w=(XX^T+λI)^(-1)Xy,使其秩不为0,可看出结构风险最小化准则的LSE;
- 最大似然估计 MLE是指找到一组参数w使得似然函数p(y|X,w, σ) 最大,等价于对数似然函数log p(y|X,w, σ) 最大。
- 最大后验估计 贝叶斯估计;MAP是指最优参数为后验分布p(w|X, y, ν, σ) 中概率密度最高的参数w。当ν → ∞时,先验分布p(w|ν) 退化为均匀分布,称为无信息先验(non-informative prior),最大后验估计退化为最大似然估计。
损失函数
交叉熵(cross entropy) https://blog.csdn.net/mieleizhi0522/article/details/80200126
特征工程
- 特征选择和特征抽取的优点是可以用较少的特征来表示原始特征中的大部分相关信息,去掉噪声信息,并进而提高计算效率和减小维度灾难
- 特征选择 选取原始特征集合的一个有效子集,使得基于这个特征子集训练出来的模型准确率最高;子集搜索—前向搜索,反向搜索、L1正则化
- 特征抽取 构造一个新的特征空间,并将原始特征投影在新的空间中。线性判断分析(LDA,监督)、PCA(无监督)
评价标准
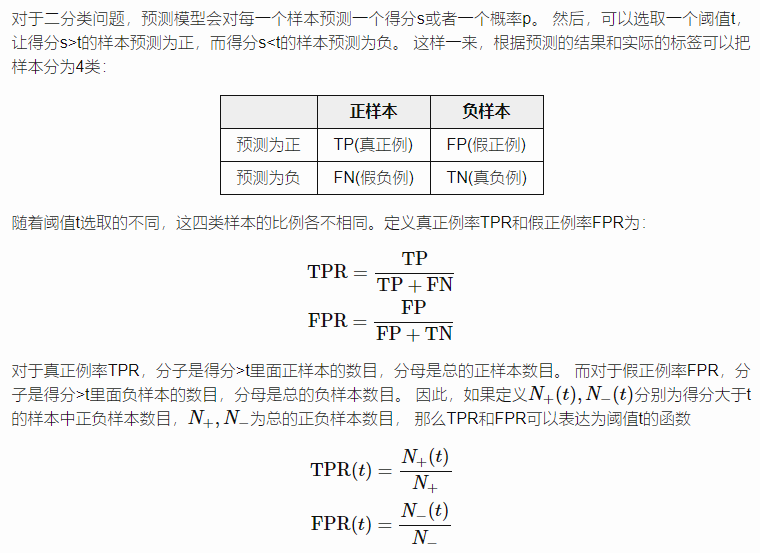
分类问题,常见的评价标准有正确率、准确率、召回率和F值,AUC,ROC,PR曲线
- 混淆矩阵


ROC(Receiver operating characteristic) AUC(Area under the curve)
https://tracholar.github.io/machine-learning/2018/01/26/auc.html
准确率、召回率、F1值等依赖于判决阈值的评估指标,AUC没有- AUC可以看做随机从正负样本中选取一对正负样本,其中正样本的得分大于负样本的概率!
超参优化
- 超参优化
- 网络结构,包括神经元之间的连接关系、层数、每层的神经元数量、激活函数的类型等;
- 优化参数,包括优化方法、学习率、小批量的样本数量等;
- 正则化系数。
- 超参设置方法:人工搜索、网格搜索和随机搜索。
网格搜索和随机搜索都没有利用不同超参数组合之间的相关性,即如果模型的超参数组合比较类似,其模型性能也是比较接近的。因此这两种搜索方式一般都比较低效。 - 自适应的超参数优化方法:贝叶斯优化和动态资源分配
- 贝叶斯优化的一个缺点是高斯过程建模需要计算协方差矩阵的逆,时间复杂度是O(n3),因此不能很好地处理高维情况。深层神经网络的超参数一般比较多,为了使用贝叶斯优化来搜索神经网络的超参数,需要一些更高效的高斯过程建模
- 动态资源分配通过一组超参数的学习曲线来预估这组超参数配置是否有希望得到比较好的结果。逐次减半,将超参数优化看作是一种非随机的最优臂问题
- 神经架构搜索
网络正则化
传统的机器学习中,提高泛化能力的方法主要是限制模型复杂度,比如采用ℓ1 和ℓ2 正则化等方式。在训练深层神经网络时,特别是在过度参数(Over-Parameterized)(过度参数是指模型参数的数量远远大于训练数据的数量)时,ℓ1 和ℓ2 正则化的效果往往不如浅层机器学习模型中显著。因此训练深度学习模型时,往往还会使用其它的正则化方法,比如数据增强、提前停止、丢弃法、集成法等。
- 权重衰减

- 提前停止
- 丢弃法(dropout) 随机丢弃一部分神经元(对应连接边)
- 集成学习的解释(每做一次丢弃,相当于从原始的网络中采样得到一个子网络)、贝叶斯学习的解释
- 循环神经网络上的dropout 当在循环神经网络上应用丢弃法,不能直接对每个时刻的隐状态进行随机丢弃,这样会损害循环网络在时间维度上记忆能力。一种简单的方法是对非时间维度的连接(即非循环连接)进行随机丢失
- 数据增强
- 通过数据增强(Data Augmentation)来增加数据量,提高模型鲁棒性,避免过拟合
- 旋转(Rotation):将图像按顺时针或逆时针方向随机旋转一定角度;
- 翻转(Flip):将图像沿水平或垂直方法随机翻转一定角度;
- 缩放(Zoom In/Out):将图像放大或缩小一定比例;
- 平移(Shift):将图像沿水平或垂直方法平移一定步长;
- 加噪声(Noise):加入随机噪声。
- 标签平滑
- 注意力机制
一个和注意力有关的例子是鸡尾酒会效应。当一个人在吵闹的鸡尾酒会上和朋友聊天时,尽管周围噪音干扰很多,他还是可以听到朋友的谈话内容,而忽略其他人的声音(聚焦式注意力)。同时,如果未注意到的背景声中有重要的词(比如他的名字),他会马上注意到(显著性注意力)。
- 可以将最大汇聚(max pooling)、门控(gating)机制来近似地看作是自下而上的基于显著性的注意力机制
- 注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均
深度学习
深层神经网络是一个高度非线性的模型,其风险函数是一个非凸函数,因此风险最小化是一个非凸优化问题,会存在很多局部最优点。
- 低维空间的非凸优化问题主要是存在一些局部最优点。
- 在高维空间中,非凸优化的难点并不在于如何逃离局部最优点,而是如何逃离鞍点。鞍点的梯度是0,但是在一些维度上是最高点,在另一些维度上是最低点
- 深层神经网络的参数非常多,并且有一定的冗余性,这导致每单个参数对最终损失的影响都比较小,这导致了损失函数在局部最优点附近是一个平坦的区域,称为平坦最小值
- 梯度下降法及其变种优缺点【An overview of gradient descent optimization algorithms】
- 发展历程——SGD -> SGDM -> NAG ->AdaGrad -> AdaDelta -> Adam -> Nadam
- BGD的时间复杂度是O(mn)
其中m是一次迭代计算的样本数(所有样本),n是样本特征数。 - SGB的时间复杂度是O(n)好吧?
- SGD一次迭代计算的样本数为1,n为样本特征数
- BatchGD 全数据集用于训练,有大量冗余计算;很慢且消耗内存;可以保证到达局部最优(非凸)或全局最优(凸)
- StochasticGD 一次用一个样本,取消冗余计算;更快、可在线;以高variance更新导致目标函数严重震荡,可能跳出局部最优点找到更好的,也可能不收敛(慢慢减少学习率)
- Mini-batchGD 一次用一部分,结合两者优势;减少参数更新variance,稳定收敛;利用矩阵优势,计算梯度效率更高?
挑战:学习率的选择策略——预定义、动态调整;不同特征的学习率(低频特征步长更大);鞍点 - Momentum 加速相关方向抑制震荡;更新公式与前一次更新值有关;下降像放球一样,在同一个方向上会越来越快,在不同梯度方向会减少更新;更快收敛和更少震荡
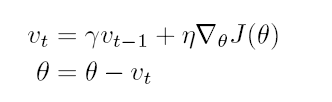
- NesterovAcceleratedGreadient 动量法盲目跟随斜坡;NAG上升前先减速,对梯度下降方向有粗略预测;用到了二阶信息,上一个下降点的二阶导(黄色部分)
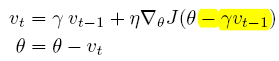
Adagrad 调整学习率(低频更新大,高频更新小,词嵌入);适合处理稀疏数据;鲁棒性提升;参数更新率不同per-parameter update;Gt,ii为对角矩阵,对角元素为过去梯度的平方和,可向量化;不需要人为调整学习率;缺陷在于平方梯度在分母,随着训练学习率会变很小,后面不再更新
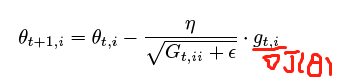
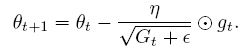
1
2
3# Adagrad update
cache += dx*82
x += - learning_rate * dx / (np.sqrt(cache) + 1e-7)Adagrad update
cache += dx82
x += - learning_rate dx / (np.sqrt(cache) + 1e-7)Adadelta Adagrad的拓展,旨在减少它单调递减的学习率;不收集过去所有梯度,而是收集过去固定值w大小的梯度量;
- RMSprop 也是Adagrad的改进,是Adadelta的第一步推导;一种泄露机制
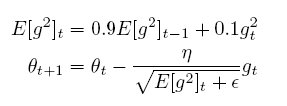
1
2
3# RMSPorp
cache = decay_rate * cache + (1 - decay_reate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + 1e-7)Adaptive Moment Estimation (Adam) Adagrad和RMSprop的结合:
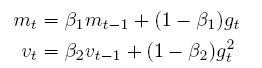
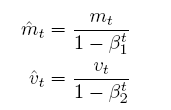
m与v分别是梯度的一阶矩(带权平均)和二阶矩(带权有偏方差),初始为0向量。Adam的作者发现它们(接近于0向量),特别是在衰减因子(衰减率)β1,β2接近于1时。为了改进这个问题,对m与v进行偏差修正(bias-corrected),偏差修正取决于时间步长t
Adam (bias-corrected)
1
2
3
4
5m = beta1 * m + (1-beta1) * dx
v = beta2 * v + (1-beta2) * (dx**2)
m /= 1-beta1**t
v /= 1-beta2**t
x += - learning_rate * m / (np.sqrt(v)) + le-7)Nadam Adam和NAG的结合(既调整学习率和粗略预测未来方向)
优化器的选择 稀疏数据用自适应学习率方法(ada系列);RMSprop,Adadelta和Adam比较相似;SGD用的很多?SGD优化时间长,依赖于初始化和退火调度,可能陷于鞍点
- 用什么优化根本不重要,因为paper的contribution不在优化问题上面。
- 控制变量法,如果baseline是用SGD的,自然也用SGD去对比,不然怎么知道是model的差异还是optimization的差异?
- 选择Adam还是SGD是工程问题不是科学问题。Adam比SGD好,是通过cross validation得出的不是通过数学推导得出的。
- SGD和Adam没有本质区别,顶多是自行车和变速山地车的区别,多了一些trick罢了。
- SGD在一些场景下效果比其他的好。
- 一些tricks
- 随机化 防止样本顺序带来的影响或偏差,更好的学习
- Batch normalization(批归一化)在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布,为解决“Internal Covariate Shift”问题——因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失对于每个隐层神经元,把逐渐向非线性函数映射后向取值区间极限饱和区靠拢的输入分布强制拉回到均值为0方差为1的比较标准的正态分布,使得非线性变换函数的输入值落入对输入比较敏感的区域,以此避免梯度消失问题。
位于X=WU+B激活值获得之后,非线性函数变换
- Scale and shift: 对净输入z(l) 的标准归一化会使得其取值集中的0 附近,如果使用sigmoid型激活函数时,这个取值区间刚好是接近线性变换的区间,减弱了神经网络的非线性性质。因此,为了使得归一化不对网络的表示能力造成负面影响,通过一个附加的缩放和平移变换改变取值区间。
- mini-batch期望和方差:目前主要的训练方法是基于小批量的随机梯度下降方法,z(l) 的期望和方差通常用当前小批量样本集的均值和方差近似估计。
- 局限性:批量归一化是对一个中间层的单个神经元进行归一化操作,因此要求小批量样本的数量不能太小,否则难以计算单个神经元的统计信息。此外,如果一个神经元的净输入的分布在神经网络中是动态变化的,比如循环神经网络,那么就无法应用批量归一化操作。
- 层归一化LN:层归一化是对一个中间层的所有神经元进行归一化。
对于K 个样本的一个小批量集合Z(l) = [z(1,l); · · · ; z(K,l)],层归一化是对矩阵Z(l) 对每一列进行归一化,而批量归一化是对每一行进行归一化 - 权重归一化:对神经网络的连接权重进行归一化,通过再参数化(Reparameterization)方法,将
连接权重分解为长度和方向两种参数 - 局部响应归一化:基于卷积的图像处理中。局部响应归一化和层归一化都是对同层的神经元进行归一化。不同的是局部响应归一化应用在激活函数之后,只是对邻近的神经元进行局部归一化,并且不减去均值。

- 提前停止
- 梯度噪声 使网络对于糟糕初始化更鲁棒,对训练复杂很深的网络有用
激活函数

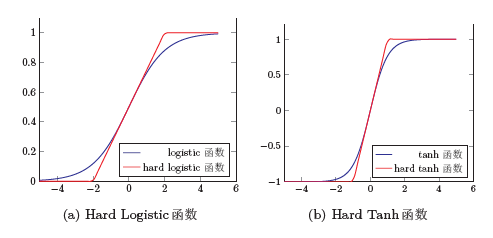
- Sigmoid S曲线;值域0-1;求导;两端饱和函数;非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢。
- Logistic函数 σ(x)=(1+exp(-x))^-1
- Tanh函数 放大平移的Logistic函数;值域为(-1,1);tanh(x)=2σ(2x)-1
- Logistic 函数和Tanh 函数都是Sigmoid 型函数,具有饱和性,但是计算开销较大。因为这两个函数都是在中间(0 附近)近似线性,两端饱和
- ReLU修正线性单元
- 原始ReLU ReLU(x)=max(0,x);
优点:1.神经元运算简单,计算上更高效;2.单侧抑制、宽兴奋边界;3.Sigmoid会导致非稀疏网络,ReLU稀疏性好;4.ReLU左饱和,右导数为1,缓解梯度消失,加速梯度收敛;
缺点:1.输出非0中心化,给后层网络引入偏置偏移,影响梯度下降效率;2.死亡ReLU问题 - LeakyReLU LeakyReLU(x)=max(0,x)+γmin(0,x)
- PReLU PReLU=max(0, x) + γ_i min(0, x),可学习参数
- ELU ELU=max(0, x) + min(0, γ(exp(x) − 1))
- Softplus函数 Softplus(x) = log(1 + exp(x)).单侧抑制、宽兴奋边界,没有稀疏激活性
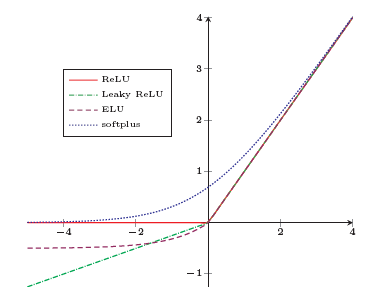
- Swish函数 自门控激活函数 swish(x) = xσ(βx)
- Maxout单元 maxout单元的输入是上一层神经元的全部原始输入,是一个向量x = [x1; x2; · · · , xd];
梯度消失和梯度爆炸
原因:深度神经网络和反向传播,根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。
- 梯度消失
- 网络太深层
- 采用了不合适的损失函数
- 梯度爆炸
- 网络太深
- 权值初始化值太大

- 解决方案:
- 预训练加微调
- 梯度剪切,权重正则(针对梯度爆炸)
- 使用不同的激活函数
- Batch normalization
- 残差结构
- 使用LSTM或GRU (有点像残差网络)
- 梯度截断 当梯度的模大于一定阈值时,就对梯度进行截断;分为按值截断、按模截断
卷积神经网络作用及发展
CNN与DNN区别:卷积、池化
- 卷积作用:局部感受野(提升表达能力和泛化能力),参数共享(减少运算量)
- 1*1卷积核作用:不影响输入输出维度,增加网络非线性表达能力,降低参数量
- 池化(下采样):最大,平均;减少参数
- 激活函数:提升表达能力和泛化能力
- Dropout:随机舍弃某些权重,降低模型复杂度,预防过拟合
- LeNet(传统CNN)->AlexNet(数据增广,dropout,relu,局部响应归一化LRN)->VGG(深)->GoogLeNet(inception增加网络宽度和深度)->ResNet(shortcut,残差网络,防止梯度消失)->DenseNet(密集连接,任何两层都有直接的连接,内存占用大)
卷积神经网络计算
- 卷积:nm的图像,kk的滤波器,卷积后为(n-k+1)(m-k+1),参数量kk+1
- Padding:卷积得到原图像size,加入层数为p=(k-1)/2
- 步长stride:(n+2p-k)/s+1,s为步长
- 单卷积核:三通道的过滤器与图像卷积,对kk3个数去加权计算和,不是分层计算
- 多卷积核:j个kk3的滤波器,得到(n-k+1)(m-k+1)j层输出,参数量kk3*j+j
- 池化:改变输入输出,不会有参数,nm的图像,kk的滤波器,s为步长,输出(n+2p-k)/s+1
- 全连接层:FC1 * FC2
循环神经网络
- 任务模式:序列到类别(分类)、同步序列到序列(词性标注)、异步序列到序列(编码器解码器、机器翻译)
参数学习:随时间反向传播(BPTT),实时循环学习算法(RTRL、前向传播)
两种算法比较:RTRL算法和BPTT算法都是基于梯度下降的算法,分别通过前
向模式和反向模式应用链式法则来计算梯度。在循环神经网络中,一般网络输
出维度远低于输入维度,因此BPTT算法的计算量会更小,但是BPTT算法需
要保存所有时刻的中间梯度,空间复杂度较高。RTRL算法不需要梯度回传,因
此非常适合用于需要在线学习或无限序列的任务中。- 长期依赖问题:如果t时刻的输出yt 依赖于t−k 时刻的输入xt−k,当间隔k 比较大时,简单神经网络很难建模这种长距离的依赖关系,称为长期依赖问题
- 梯度爆炸:权重衰减(通过给参数增加ℓ1 或ℓ2 范数的正则化项来限制参数的取值范
围,从而使得γ ≤ 1)、梯度截断(当梯度的模大于一定阈值时,就将它截断成为一个较小的数) - 梯度消失(RNN主要问题):改变模型,ht = ht−1 + g(xt, ht−1; θ), (6.50)
这样ht 和ht−1 之间为既有线性关系,也有非线性关系,但有记忆容量问题—增加额外存储,选择性遗忘 - LSTM和GRU:基于门控的循环神经网络
- LSTM:LSTM网络引入一个新的内部状态(internal state)ct 专门进行
线性的循环信息传递,同时(非线性)输出信息给隐藏层的外部状态ht。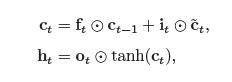
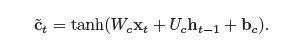
- LSTM网络中的“门”是一种“软”门,取值在(0, 1) 之间,表示以一定的比例运行信息通过。
- 输入门:输入门it 控制当前时刻的候选状态˜ct 有多少信息需要保存
- 遗忘门:遗忘门ft 控制上一个时刻的内部状态ct−1 需要遗忘多少信息
- 输出门:输出门ot 控制当前时刻的内部状态ct 有多少信息需要输出给外部状态ht。
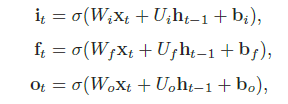
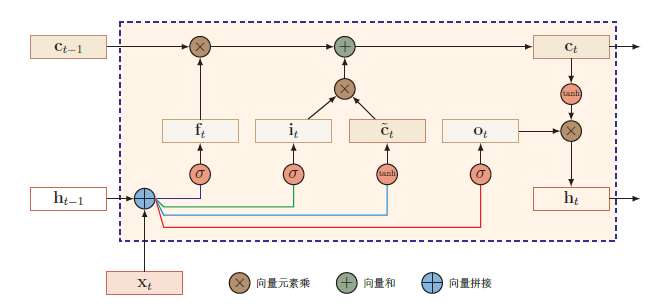
LSTM网络中,记忆单元c 可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。记忆单元c 中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆,因此称为长的短期记忆(long short-term memory)。
LSTM变体:
- 无遗忘门的LSTM Schmidhuber最早提出,ct会不断累加
- peephole连接 三个门不但依赖于输入xt 和上一时刻的隐状态ht−1,也依赖于上一个时刻的记忆单元ct−1。
耦合输入门和遗忘门 LSTM网络中的输入门和遗忘门有些互补关系,同时用两个门比较冗余。
门控循环单元(GRU) GRU将输入门与和遗忘门合并成一个门:更新门。同时,GRU也不引入额外的记忆单元,直接在当前状态ht 和历史状态ht−1 之间引入线性依赖关系。
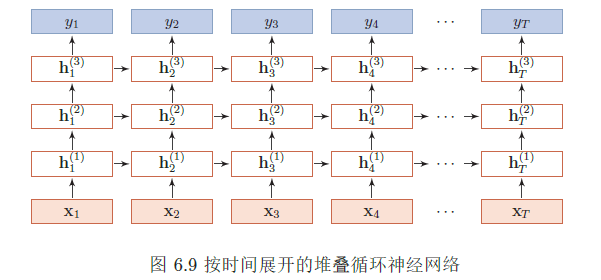
深层循环神经网络 增加循环神经网络的深度主要是增加同一时刻网络输入到输出之间的路径xt →yt,比如增加隐状态到输出ht → yt,以及输入到隐状态xt → ht 之间的路径的深度。
- 堆叠循环神经网络
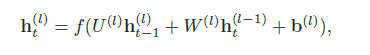
- 双向循环神经网络 一个时刻的输出不但和过去时刻的信息有关,也和后续时刻的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定
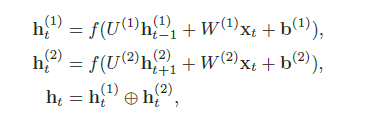
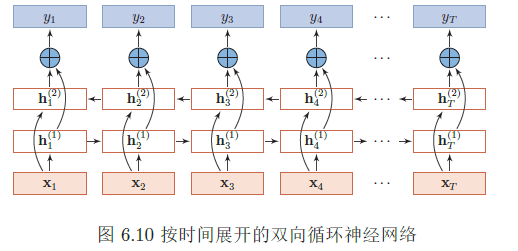
注意力机制
参数初始化
- 在感知器和logistic 回归的训练中,我们一般将参数全部初始化为0
- 对称权重:神经网络训练,前向计算时所有隐层神经元激活值相同,导致深层无区分性
- 参数初始化过小:多层传递信号慢慢消失;使sigmoid丢失非线性(0附近近似线性)
- 参数初始化过大:sigmoid后激活值变得饱和,导致梯度接近于0
- 常用初始化方法:Gassian分布初始化、均匀分布初始化(Xavier 初始化)